دانلود با لینک مستقیم و پر سرعت .
-1) معرفی بانک اطلاعاتی
در بین سالهای 1992 و1993 شرکت مایکروسافت سه محیط جدید پایگاه داده ها را تحت ویندوز عرضه کرد که شامل فاکسپرو برای ویندوز و ویژوال بیسیک 3 ، و اکسس1 بود.این شرکت اعلام کرد که اکسس پایگاه داده مورد استفاده هر فرد میباشد. و در مدت 95 روز ، هفتصدوپنجاه هزار نسخه به فروش رفت. فاکسپرو برای ویندوز با هدف توسعه کار پایگاه داده های شرکت بین المللی بورلند برای ویندوز به وجود آمد هم اکسس و هم فاکسپرو در بازار از پاراداکس محصول شرکت بورلند پیشی گرفتند که این برنامه مدتی پس از اکسس1، به بازار عرضه شد. تا سال 1996 شرکت مایکروسافت بیش از 4 میلیون نسخه از اکسس، ویرایش های 1 و 1.1 و2 را فروخت و تعداد استفاده کنندگان ویژوال بیسیک ویرایشهای یک،دو، سه را تا 2 میلیون نفر بالابرد.
1-2) بانک اطلاعاتی چیست ؟
از بانک اطلاعاتی تعاریف گوناگونی شده است که تعریف زیراز همه جامعتر به نظر می رسد : بانک اطلاعاتی مجموعه ای سازمان یافته از اطلاعات و داده های مرتبط به هم است. داده ها عبارتند از : حقایق و ارقام یک موضوع خاص و اطلاعات عبارتنداز : نتایجی که از ترکیب داده ها حاصل می گردند. موسسات و سازمانها معمولا به دو صورت سیستم های اطلاعاتی خود را تشکیل داده از آنها استفاده می کنند.
1-2-1) استفاده از سیستمهای اطلاعاتی ساده
در این روش ،داده ها در فایل های جدا گانه قرار می گیرند وبرای استفاده از داد ه های موجود در آن فایل ها ،سیستمهای جداگانه ای طرا حی می شوند. به این نوع سیستمهای اطلا عاتی سیستم پردازش فایل ها می گویند.
1-2-2) استفاده از بانکهای اطلاعاتی
در این روش داد های موجود، به صورت مجتمع یا بانک مورد استفاده قرار می گیرند. در چنین سیستمی کاربر می تواند بدون سر درگمی و یا صرف وقت اندکی،اطلاعات مورد نیاز خود را از داده های موجود مجتمع اخذ کند.امروزه اکثر موسسات و سازمانها سعی می کنند از این سیستم اطلاعاتی استفاده کنند. برای پی بردن به تفاوت دو روش ذکر شده ، موسسه ای را در نظر بگیرید که داده های مربوط به حقوق کارمندان ، بیمه ،تنبیه و تشویق را در چهار فایل جدا گانه قرار داده برای اخذ خرو جیهای مورد نیاز ، سیستم های جدا گانه ای برای آنها نوشته است شکل(2-1).
1-2-3) مزایای استفاده از بانک اطلاعاتی
با یک نگاه ساده به شکل(1-1)مشخص می شود که داده های زیادی از قبیل نام کارمندان ،شمار کارمندی،تاریخ استخدام در فایلهای مختلف مشترک می باشند.این امر موجب استفاده بیهوده از حافظه می گردد. اگر در وضیعت کارمندان موسسه تغییراتی ایجاد شود،این تغییرات باید در تمام فایها اعمال شود،اگر این تغییرات در یک یا چند فایل اعمال نشود،منجر به اخذ گزارشهای متناقضی می گردد که در این صورت به گزارش های حاصل از سیستم اطمینانی نیست.
شکل(1-1) سیستم پردازش فایل
1-2-4) معایب استفاده از سیستم بانک اطلاعاتی
بانک اطلاعاتی با همه مزایایش معایبی نیز دارد که این معایب در مقایل مزایای بانک اطلاعاتی ناچیز می باشد.از جمله:
1. چون طراحی بانکهای اطلاعاتی ساده نیست جهت ایجاد آن به متخصصان ماهری نیاز است.
2. به دلیل متمرکز بودن سیستم اطلاعاتی امکان آسیب پذیری سیستم زیاد است . یعنی اگر یک قسمت از سیستم از کار بیفتد،ممکن است در کار بقیه قسمتها خلل ایجاد شود.
1-3) بانک اطلاعاتی و ویژوال بیسیک
در ویژوال بیسیک می توان برنامه هایی نوشت که بانک اطلاتی را ایجاد و ویرایش کنند سه نوع با نک اطلاعاتی در ویژوال بیسیک قابل استفاده اند.
1. بانکهای اطلاعاتی اکسس . این نوع بانکهای اطلاعاتی را می توان از طریق اکسس ما یکروسافت یا ویژوال بیسیک ایجاد ومدیریت نمود.
2. بانکهای اطلاعا تی خارجی . این نوع بانکهای اطلاعاتی شامل بانکهای اطلاعاتی پارادوکس ، dBase III، dBase IV و FAXPRO است.این نوع بانکهای اطلاعاتی را می توانید در ویژوال بیسیک ایجاد ومدیریت کنید
3. بانکهای اطلاعاتی خارجی .ODBC پیکربندی این نوع بانکهای اطلاعاتی،مشتری/کارگزار است وشامل اوراکل وServer SQL است.
1-4) ساختار بانک اطلاعاتی
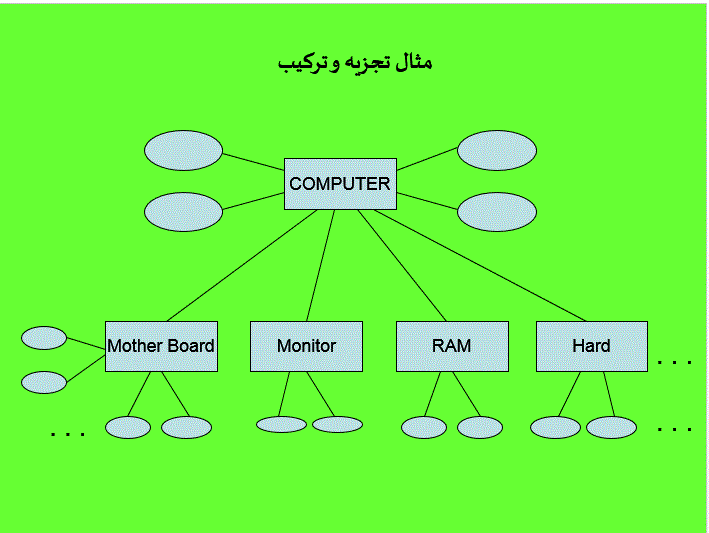
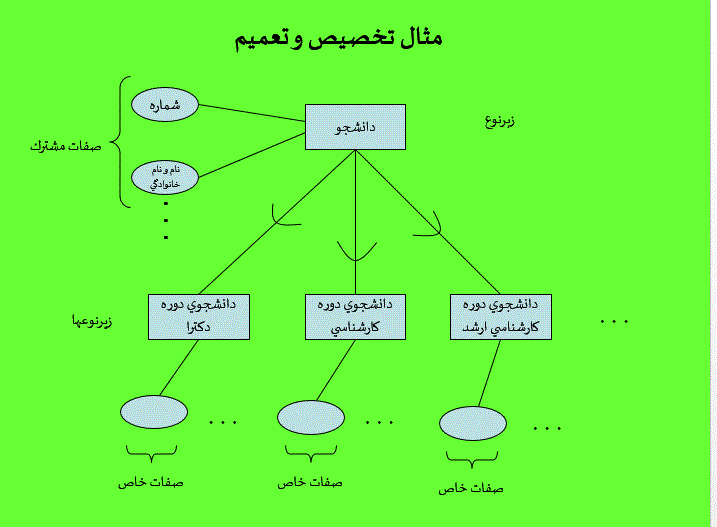
رکورد: به اطلاعات به هر فرد ،شیء یا هر چیز دیگری که به بانک اطلاعاتی وارد شود،رکورد گویند.به عنوان مثال اگر یک بانک اطلاعاتی از دانشجویان را در نظر بگیریم،به کل اطلا عات هر دانشجو که در فایل ذخیره می شود یک رکورد گفته می شود. به همین دلیل،می گویند که بانک اطلاعاتی مجموعه ای از رکورد هاست.
فیلد: به هر یک از اجزای رکورد ،فیلد گفته می شود . به عنوان مثال،در بانک اطلاعاتی دانشجویان نام دانشجو یک فیلد است وشماره دانشجویی فیلد دیگری است.
نام فیلد: هر فیلد دارای نامی است که با استفاده از آن مراجعه می شود نام فیلد طوری انتخاب می شود که بیانگر محتویات آن فیلد باشد. مثلا بهتر است نام فیلد شماره دانشجویی با STNO یا ID مشخص گردد.نام فیلد با ترکیبی از حروف الفبا ،ارقام و خط ربط ساخته می شود.
نوع فیلد: هر فیلد دارای نوعی است . مثلا نام دانشجو از نوع متن(Text )،شماره دانشجویی از نوع عدد صحیح ،معدل دانشجو از نوع عدد اعشاری و تاریخ قبولی دانشجو از نوع تاریخ است انواعی که فیلدها در بانک اطلاعاتی اکسس می توانند داشته باشند در شکل(1-1) آمده است
اندازه فیلد: اندازه فیلد مشخص می کند که فیلد چند بایت از فضای حافظه را بایت اشغال کند.در مورد فیلدهای کاراکتری حداکثر تعداد کاراکترها ودر مورد فیلد های عددی ، میزان حافظه بر حسب بایت مشخص می شود.
1-5) جدول در بانک اطلاعاتی
اطلاعات موجود در بانک اطلاعاتی به صورت جدول ذخیره می شوند و هر جدول دارای تعدادی سطر و ستون است. نمونه ای از جدول را در شکل(1-4) می بینید . در این جدول ، می خواهیم اطلاعات دانشجویان را وارد کنیم.بانک اطلاعاتی ممکن است شامل یک یا چند جدول باشد.
نوع فیلد توضیح
Text برای فیلدهایی که محتویات آنها متنی است.مثل نام دانشجو،به کارمی رود .چون کار برد آن زیاداست.نوعی انتخابی پیش فرض است در صورت انتخاب این نوع ،حداکثر طول آن نیز باید مشخص گردد.
Numeric برای فیلدهایی که نوع آنها عددی است به کار می رود وبه چند دسته تقسیم می شود که در جدول(2-2) مشاهده می شوند .
Memo برای فیلدهایی به کار می رود که به عنوان توضیحات مورد استفاده قرار می گیرند. فیلدهایی که حاوی مقدار زیادی از متن باشند از این نوع انتخاب خواهند شد.
Boolean برای فیلدهایی که دارای ارزش منطقی درستی یا نا درستی اند به کار می رود.
Currency برای فیلدهایی از نوع پولی به کار می رود و دارای 4 رقم اعشار است جدول(2-2).
Date/Time برای فیلدهایی از نوع زمان و تاریخ مثل سا عت ورود کارمند و تاریخ استخدام کارمند به کار می رود.
جدول(1-1) انواع فیلدها در بانک اطلاعاتی اکسس
نوع داده عددی ارقام اعشار حافظه مورد نیاز (بایت) بازه قابل قبول
Integer - 2 32768- تا 32767
Long - 4 2147483648- تا 2147483648
Byte - 1 0 تا 255
Single 7 4 38E*4/3- تا E38*4/3
Double 15 8 308E10*797/1- تا 308E10*797/1
Currency 4 4 5808/922337203685477- تا 5808/922337203685477
جدول(1-2) انواع فیلدهای عددی در بانک اطلاعاتی اکسس
شکل(1-2) نمونه ای از جدول اطلاعاتی در بانک اطلاعاتی
1-6) سیستم مدیریت پایگاه دادهها
سیستم مدیریت پایگاه دادهها (DBMS )، یک یا مجموعهای از چند برنامه کامپیوتری است که برای مدیریت پایگاه دادهها، مجموعه عظیمی از دادههای ساخت یافته و عملیات اجرایی بر روی دادههای درخواستی کاربران، طراحی شده است. سیستمهای حسابداری، منابع انسانی و پشتیبان مشترک، نمونههایی از کاربرد سیستم مدیریت پایگاه دادهها هستند. این سیستمها که پیشتر فقط در شرکتهای بزرگ مطرح بودند، اخیرا بخش مهمی در شرکت محسوب میشوند. تفاوت سیستمهای مدیریت پایگاه دادهها با برنامههای پایگاه دادهها در این است که سیستمهای مذکور به عنوان موتور سیستم چندکاربره طراحی شدهاند. این سیستمها برای ایفای چنین نقشی، در کرنل مالتی تسکینگ خصوصی با پشتیبان شبکهای از پیش ساخته شده، قرار گرفتهاند. یک برنامه پایگاه داده نمونه، این گونهها را در درون خود ندارد، اما شاید بتواند با کمک سیستم عامل از عملکرد چنین گونههایی پشتیبانی کند.
1-7) پایگاه دادههای پیمایشی
رشد کاربری کامپیوتر، پیدایش سیستمهای پایگاه دادههای همه منظوره را موجب گردید. و در اواسط 1960 چنین سیستمهایی در بخش تجاری به کار گرفته شد. چارلزبچ من، نویسنده یکی از چنین محصولاتی با نام IDS، گروه Database Task Group را بنیان نهاد که این گروه مسوول ایجاد و استاندارد سازی COBOL شد. آنها در سال 1971 استاندارد خود را عرضه نمودند. این استاندارد Codasyle approach نام داشت. این شیوه مبتنی بر پیمایش دستی مجموعه دادهها بود. هنگامی که پایگاه دادهها برای اولین بار برنامه را باز میکرد، به اولین رکورد در پایگاه دادهها و به همین ترتیب نیز به سایر بخشهای داده نیز اشاره میشد. برنامه نویس برای دسترسی به یک رکورد خاص مجبور بود تا این اشارهگرها رابه ترتیب دنبال کند تا به رکورد موردنظر برسد. در query های ساده مانند " یافتن تمام افرادی که در سوئد زندگی میکنند " باید برای جستجو در کل مجموعه دادهها برنامه نویسی میشد و دستوری به نام find وجود نداشت. شرکت IBM سیستم مدیریت پایگاه دادههایی به نام IMS داشت. این سیستم از نظر مفهوم مشابه codasyle بود، اما برخلاف آن که از مدل شبکهای استفاده مینمود، IMS مدل سلسله مراتبی را به کار میبرد.
1-8) پایگاه دادههای رابطهای
ادگار کاد که در شرکت آیبیام کار میکرد در سال 1970 مقالاتی در زمینه شیوه جدیدی برای ساخت پایگاه دادهها نوشت. یکی از مقالات وی که Relational Model of Data for Shared Data Bank نام داشت، به بررسی سیستم جدیدی برای ذخیره سازی و کار با پایگاه دادههای بزرگ پرداخته بود. در این شیوه به جای اینکه رکورد به صورت رکوردهای free-form همانگونه که در روش codasyle آمده بود، ذخیره شوند، از جدولی با رکوردهایی با طول ثابت استفاده میشد.چنین سیستمی برای ذخیره سازی پایگاه دادههای پراکنده و در جاییکه بعضی از دادههای رکورد خالی هستند، کارآیی ندارد. مدل رابطهای این مشکل را حل کرده است. بدین صورت که دادهها به یکسری جدول تقسیم میشوند و عناصر اختیاری از جدول اصلی خارج میگردند و در صورت نیاز در جدول قرار میگیرند. چنین سیستمی برای ردیابی اطلاعات کاربران، اسامی و نشانی آنان و غیره به کار میرود. دادهها در روش پیمایشی در یک رکورد جای میگیرند و آیتمهایی که مورد استفاده قرار نگیرند، در پایگاه دادهها نیز نخواهند بود. دادهها در شیوه رابطهای در جداول جداگانهای، مثلا جدول اسامی، جدول نشانیها و غیره جای میگیرند. برقراری ارتباط بین اطلاعات نکته مهم در این سیستم است. درمدل رابطهای بعضی از بیتهای اطلاعات به عنوان کلید معرفی میشوند و منحصرا بیانگر رکورد خاصی هستند. هنگامی که اطلاعات کاربر جمع آوری میشود، میتوان این اطلاعات را که در جداول اختیاری ذخیره میشوند، با جستجوی کلید مربوطه یافت.
1-9) پایگاه دادههای چند بعدی
پایگاه دادههای رابطهای توانست به سرعت بازار را تسخیر کند، هرچند کارهایی نیز وجود داشت که این پایگاه دادهها نمیتوانست به خوبی انجام دهد. به ویژه به کارگیری کلیدها در چند رکورد مرتبط به هم و در چند پایگاه داده مشترک، کندی سیستم را موجب میشد. برای نمونه برای یافتن نشانی کاربری با نام دیوید، سیستم رابطهای باید نام وی را در جدول کاربر جستجو کند و کلید اصلی (primary key ) را بیابد و سپس در جدول نشانیها، دنبال آن کلید بگردد. اگر چه این وضعیت از نظر کاربر، فقط یک عملیات محسوب، اما به جستجو درجداول نیازمند است که این کار پیچیده و زمان بر خواهد بود. راه کار این مشکل این است که پایگاه دادهها اطلاعات صریح درباره ارتباط بین دادهها را ذخیره نماید. میتوان به جای یافتن نشانی دیوید با جستجو ی کلید در جدول نشانی، اشارهگر به دادهها را ذخیره نمود. در واقع، اگر رکورد اصلی، مالک داده باشد، در همان مکان فیزیکی ذخیره خواهد شد و از سوی دیگر سرعت دسترسی افزایش خواهد یافت. چنین سیستمی را پایگاه دادههای چند بعدی مینامند. این سیستم در هنگامی که از مجموعه دادههای بزرگ استفاده میشود، بسیار سودمند خواهد بود. از آنجاییکه این سیستم برای مجموعه دادههای بزرگ به کار میرود، هیچگاه در بازار به طور مستقیم عمومیت نخواهد یافت.
1-10) پایگاه دادههای شیء
اگر چه سیستمهای چند بعدی نتوانستند بازار را تسخیر نمایند، اما به توسعه سیستمهای شیء منجر شدند. این سیستمها که مبتنی بر ساختار و مفاهیم سیستمهای چند بعدی هستند، به کاربر امکان میدهند تا اشیاء را به طور مستقیم در پایگاه دادهها ذخیره نماید. بدین ترتیب ساختار برنامه نویسی شیء گرا (object oriented ) را میتوان به طور مستقیم و بدون تبدیل نمودن به سایر فرمتها، در پایگاه دادهها مورد استفاده قرار داد. این وضعیت به دلیل مفاهیم مالکیت (ownership) در سیستم چند بعدی، رخ میدهد. در برنامه شیء گرا (OO)، یک شیء خاص "مالک " سایر اشیاء در حافظه است، مثلا دیوید مالک نشانی خود میباشد. در صورتی که مفهوم مالکیت در پایگاه دادههای رابطهای وجود ندارد.
1-11) ویژگیهای سیستم مدیریت پایگاه دادهها
پس از این مقدمه به توصیف سیستم مدیریت پایگاه دادهها میپردازیم. سیستم مدیریت پایگاه دادهها، مجموعهای پیچیده از برنامههای نرمافزاری است که ذخیره سازی و بازیابی دادههای (فیلدها، رکوردها و فایلها) سازمان را در پایگاه دادهها، کنترل میکند. این سیستم، کنترل امنیت و صحت پایگاه دادهها را نیز بر عهده دارد. سیستم مدیریت پایگاه دادهها، درخواستهای داده را از برنامه میپذیرد و به سیستم عامل دستور میدهد تا دادهها ی مناسب را انتقال دهد. هنگامی که چنین سیستمی مورد استفاده قرار میگیرد، اگر نیازمندیهای اطلاعاتی سازمانی تغییر یابد، سیستمهای اطلاعاتی نیز آسانتر تغییر خواهند یافت. سیستم مذکور از صحت پایگاه دادهها پشتیبانی میکند. بدین ترتیب که اجازه نمیدهد بیش از یک کاربر در هر لحظه، یک رکورد را به روز رسانی کند. این سیستم رکوردهای تکراری را در خارج پایگاه دادهها نگاه میدارد. برای مثال، هیچ دو مشترک با یک شماره مشتری، نمیتوانند در پایگاه دادهها وارد شوند. این سیستم روشی برای ورود و به روز رسانی تعاملی پایگاه دادهها فراهم میآورد. یک سیستم اطلاعات کسب و کار از موضوعاتی نظیر (مشتریان، کارمندان، فروشندگان و غیره) و فعالیتهایی چون (سفارشات، پرداختها، خریدها و غیره) تشکیل شده است. طراحی پایگاه دادهها، فرایند تصمیم گیری درباره نحوه سازماندهی این دادهها در انواع رکوردها و برقراری ارتباط بین رکوردهاست.سیستم مدیریت پایگاه دادهها میتواند ساختار دادهها و ارتباط آنها را در سازمان به طور اثر بخش نشان دهد. سه نوع مدل متداول سازمانی عبارتند از: سلسله مراتبی، شبکهای و رابطهای. یک سیستم مدیریت پایگاه دادهها ممکن است یک، دو یا هر سه روش را فراهم آورد. سرورهای پایگاه دادهها، کامپیوترهایی هستند که پایگاه دادههای واقعی را نگاه میدارند و فقط سیستم مدیریت پایگاه دادهها و نرمافزار مربوطه را اجرا میکنند. معمولا این سرورها کامپیوترهای چند پردازندهای با آرایههای دیسک RAID برای ذخیره سازی میباشند.
1-12) سیستمهای متداول مدیریت پایگاه دادهها
Closed source :
• IBM (DB2)
• FileMaker, Inc (FileMaker Pro)
• IBM (IMS)
• Informix
• Computer Associates (Ingres)
• Borland (InterBase)
• Micosoft (Microsoft SQL Server)
• Microsoft (Microsoft Access)
• Mimer AB (Mimer SQL)
• Oracle
• Sybase
• NCR Corporation (Teradata)
Open Source :
• Sleepycat software (Berkeley DB )
• IBPhoenix (Firebird)
• My SQL AB (My SQL)
• PostgreSQL
• MaxDB
• SQLite
1-13) تعریف کلی از اکسسAccess
اکسس ابزاری برای تولید بانکهای اطلاعاتی رابطه ای است. بانکهای اطلاعاتی امکان گردآوری انواع اطلاعات را برای ذخیره سازی ،جستجو و بازیابی فراهم میکند.
1-13-1) اجزاء بانک اطلاعاتی اکسس
1. Table
2. Query
3. Form
4. Report
5. Macros
6. Modules
• Table : (جدول ) هر جدول برای نگهداری دادههای خام بانک اطلاعاتی است.دادهها را شما در جدول وارد میکنید.جداول سپس این دادهها را به شکل سطرها و ستونهایی سازماندهی می کند.
• Query : هر پرس و جو برای استخراج اطلاعات مورد نظر از یک بانک اطلاعاتی مورد استفاده قرار میگیردهر پرس و جو میتواند گروهی از رکوردها را که شرایط خاص دارا هستند انتخاب کند.پرس و جوها را میتوان بر اساس جداول یا پرس و جوهای دیگر آماده نمود. با استفاده از پرسوجوها میتوان رکوردهای بانک اطلاعاتی را انتخاب کرد، تغییر داد و یا حذف نمود.
• Form : متداول ترین روش استفاده از فرمها،برای ورود و نمایش دادهها است.
• Report : گزارش ها میتوانند بر اساس جدول ،پرسوجوها باشند ،قابلیت گزارش چاپ دادهها میباشدگزارشها را میتوان بر اساس چند جدول و پرسوجو تهیه نمود تا رابطه بین دادهها را نشان داد.
• Macro : ماکروها به خودکار کردن کارهای تکراری ،بدون نوشتن برنامههای پیچیده یا فراگیری یک زبان برنامه نویسی ، یاری میکند، در واقع ماکروها یکسری قابلیتهایی هستند که امکان سریع سازی را فراهم میسازند.
• Modules : محیط بسیار قوی و با کیفیت برای برنامهنویسی محاسبات و عملیات پیچیده روی سیستم بانک اطلاعاتی.
• Data : هرگونه اطلاعات لازم و کاربردی درباره یک موجودیت را یک داده میگویند.
• Fild : به هر ستون یک جدول که در بر گیرنده کلیه اطلاعات مربوط به آن ستون میباشد و بخشی از یک موجودیت را تشکیل می دهد فیلد گفته میشود.
• Record : به هر سطر یک جدول که اطلاعات مربوط به یک موجودیت را نشان میدهد ، رکورد گویند.
• پایگاه دادهی ارتباطی: پایگاه دادههای ارتباطی، مجموعهای از جدولهای داده است که یک فیلد مشترک در هر یک از جدولهای موجود دارد و از طریق آن میتوان دادهها را بهم ربط داد.به این مدل از پایگاه دادهها ، پایگاه دادههای ارتباطی RelationShip میگویند.
1-14) نمودار گردش داده (DFD )
نمودار گردش داده یا DFD (data flow diagram) را ترسیم کنید ، این نمودار می تواند به ما نشان دهد که داده های خروجی و ورودی هر یک از اجزا چیست ، وضعیت گردش آنها به چه ترتیب است .
در مورد ترسیم این نمودارمی بایستی تمام گردش کاربه دقت رسم شود چرا که به عنوان یک نمودار عملیاتی مورد استفاده قرارمی گیرد .
شکل ( 1 - 3 ) DFD سیستم دفترچه تلفن و یادداشتهای روزانه
1-15) فرآیندها
فرآیندها نشان می دهند که سیستمها چه کاری انجام می دهند. هر فرآیند دارای یک یا چند داده ورودی است و یک یا چند داده خروجی را تولید می کند. فرآیند ها در DFD با دایره مشخص می شوند. هر فرآیند دارای یک نام و شماره منحصر بفرد است که در دایره نشان دهنده فرآیند قرار می گیرد.
1-16) فایلها یا انبار داده
فایل یک انبار داده است که داده ها را ذخیره می کند . فرآیندها می توانند داده ها را وارد انبار داده ها کنند. یا از آنها بازیابی نمایند هر انبار داده در DFD با یک خط پهن نمایش داده می شود و دارای نام منحصر بفرد است.
1-17) نهادهای خارجی
نهادهای خارجی در خارج از سیستم قرار دارند،اما یا داده ها را وارد سیستم می کنند یا از خروجی سیستم استفاده می کنند. طراحان بر روی این نهادها کنترلی نداند.آنها ممکن است مشتریان سازمان یا افراد دیگری باشند که سازمان با آنها تعامل دارد. اگر در حال مدل سازی یک بخس در سازمان باشیم بخش ها ی دیگر به عنوان نهادهای خارجی منظور می شوند. نهادهای خارجی با مربع یا مستطیل نمایش داده می شوند. نهادهای خارجی که داده هایی را وارد سیستم می کنند، منبع نامیده می شوند و نهادهای خارجی که از داده های سیستم استفاده می کنند حفره نامیده می شوند.
1-18) جریان های داده
جریان های داده حرکت داده ها را در سیستم مدل سازی می کنند و یا خطوطی مشخص می شوند که مولفه های سیستم را به وصل می کند. جهت جریان توسط فلش مشخص می شود و نام جریان داده در کنار خط جریان ذکر می شود. جریان های داده در سیستم می تواند در موارد زیر قرار گیرند:
• بین دو فرآیند
• از انبار داده به فرآیند
• از فرآیند به انبار داده
• از منبع به فرآیند
• از فرآیند به حفره
بر روی جریان های بین نهادهای خارجی کنترلی نداریم و در نتیجه نمی توانیم آنها را مدل سازی کنیم. به طور مشابه ، انبار داده ها غیر فعال هستند و جریان داده ای از یک انبار داده به انبار دیگر وجود ندارد. برای انتقال داده ها بین دو انبار داده نیاز به یک فرآیند است.
1-19) توصیف سیستم ها با نمودارهای جریان داده
اکنون سیستمهای را توصیف می کنیم که با استفاده از این نمادها مدل سازی می شود. متداولترین روش شروع کار این است که مدل سازی سیستم را با یک فرآیند شروع کنیم.DFD که این کار را انجام می دهد نمودار بستر را نام دارد. این نمودار تمام نهادهای خارجی را که با سیستم تعامل دارند و جریان های داده بین این نهادهای خارجی و سیستم را نشان می دهد.
1-20) ویژگیهای DFD خوب
DFDها ویژگیهای زیادی دارند که استفاده از آنها می توان تعیین کرد که آیا DFD خود توصیف کامل و بدون ابهام است یا خیر. این ویژگیها عبارتند از:
• عدم وجود ساختارهای فلو چارت
• حفاظت از داده ها
• قواعد نامگذاری خوب
1-20-1) تفاوت های بین فلو چارت ها و نمودارهای جریان داده
احتمالا با فلو چارت های برنامه آشنایی دارید. فلو چارت ها چارگوشهایی هستند که نشان دهنده محاسبات، تصمیم گیریها، تکرارها و حلقه ها هستند. دقت کنید که DFDها فلو چارت های برنامه نیستند و نباید حاوی دستورات کنترلی باشند.
2 – 1 ) طراحی پایگاه داده دفترچه تلفن و یادداشتهای روزانه
برای درست کردن پایگاه داده ابتدا باید به نکات زیر توجه کرد
1- اطلاعات شماره تلفن مانند نام ، نام خانوادگی و تلفن که در این فیلد ها ، فیلد تلفن از نوع کلید است
2- اطلاعات مربوط به یادداشتهای روزانه که شامل فیلد های تاریخ و یادداشت می باشد
بنا به اطلاعات بالا ما نیاز به دو جدول در پایگاه داده هایمون داریم که عبارتند از
1- جدول اطلاعات تلفن
2- جدول یادداشتهای روزانه
2-1-1 ) جدول اطلاعات تلفن
این جدول از فیلدهای نام ، نام خانوادگی و تلفن تشکیل شده است مانند شکل ( 2 – 1 ) .که تلفن از نوع کلید اصلی می باشد .
کلید اصلی نام فیلد نوع فیلد اندازه فیلد ( بایت ) پیش فرض
* name Text 50
* Family Text 50
Tel Text 50
جدول ( 2 – 1 ) جدول اطلاعات تلفن
2-1-2 ) جدول یادداشتهای روزانه
این جدول از فیلد های تاریخ و یادداشت تشکیل شده است که هیچ یک از فیلد ها کلید نمی باشد زیرا فیلدی که از نوع کلید باشد نمی تواند تکراری باشد و ما در این جدول تاریخ را از نوع کلید قرار ندادیم چون ممکن است در یک روز بیشتر از یک یادداشت داشته باشیم . که اطلاعات این جدول را در شکل ( 2 – 2 ) نمایش داده شده است .
کلید اصلی نام فیلد نوع فیلد اندازه فیلد ( بایت ) پیش فرض
* Date Text 50
* Yadasht Text 50
جدول ( 2 – 2 ) جدول یادداشتهای روزانه
مقدمه
ویژوال بیسیک یکی از زبانهای نسل جدید است که در محیط ویندوز کار میکند و امکانات فوق العاده ای دارد .ویژگی شی گرایی درآن موجب شده است تا در اغلب کاربرد ها به عنوان یک زبان قدرتمند ظاهر شود.
بیسیک زبانی است که دوران تحول زیادی را پشت سر گذاشته است. اولین نسخه از زبان بیسیک طوری بود که برنامه نویسی در آن دشواری خاصی داشت.امروزه با جدیدترین نسخه بیسیک به نام ویژوال بیسیک سر و کار داریم. این زبان در محیط ویندوز قدرت فوق العاده ای دارد. به طوری که از سبک برنامه نویسی شی گرایی پیروی می کند.تولید برنامه ها در این زبان بسیار ساده است، چرا که بخش زیادی از برنامه را کامپایلر زبان تولید می کند.
3-1) سبک های برنامه نویسی
به طور کلی سه سبک برنامه نویسی تاکنون مورد استفاده قرار گرفته اند،سبک سنتی، سبک برنامه نویسی ساخت یافته و سبک برنامه نویسی شیءگرا.
3-1-1) سبک برنامه نویسی سنتی
در سبک برنامه نویسی سنتی،نوشتن برنامه ها ورد یابی اجرای آنها بسیار دشوار بود، زیرا با استفاده از دستور GOTO کنترل اجرای برنامه از هر نقطه ای به نقطه دیگر منتقل می شد.نگهداری این برنامه ها و انجام تغییرات در آنها برای پاسخگویی به وضعیت و نیاز های جدید بسیار دشوار بود.
3-1-2) برنامه نویسی ساخت یا فته
در دهه 1960 میلادی، تولید بسیاری از نرم افزار ها با مشکل مواجه شد. زمان بندی تولید نرم افزار به تاخیر می افتاد،هزینه ها بالا بود و در نتیجه بودجه تولید نرم افزار افزایش می یافت و نرم افزار تولیدی نیز از قابلیت اعتماد بالایی بر خورد دار نبوده است.تولید کنند گان نرم افزار به این نتیجه رسیدند که تولید نرم افزار مشکل تر از آن چیزی است که در مورد آن تصور می شود.تحقیقاتی برای برطرف کردن مشکلات به عمل آمد، منجر به برنامه نویسی ساخت یا فته شد. برنامه نویسی ساخت یا فته، روش منظمی برای نوشتن برنامه هاست و منجر به نوشتن برنامه هایی می شود که خوانایی آنها بالاست،تست و اشکال زدایی آنها راحت تر و اصلاح آنها ساده تر است.
در برنامه نویسی ساخت یافته،برنامه به صورت مجمو عه ای از فعالیت ها تصور می شود که باید بر روی داده ها انجام شوند.دراین روش ، هر کار پیچیده ای، به مجموعه ای ازکارهای کوچکتر تجزیه می شود تا اینکه کار های ایجاد شده قابل درک باشند.به عبارت دیگر،برنامه نویس سعی می کندتوابعی بنویسید که نیازمندیهای سیستم را برآورده کنند.
برنامه نویسی ساخت یا فته،روش موفقی برای حل مسایل پیچیده است، اما مشکلات خاص خودش را دارد . در این روش ، داده ها از فعالیتها (توابعی)که آنها را پردازش می کنند جداست. وقتی حجم داده ها زیاد می شود، نگهداری آنها مشکل می شود. هر چه بیشتر با داده ها کار می کنید، با مشکلات بیشتری مواجه می شوید.
بعضی از زبانهای برنامه سازی که برای برنامه نویسی ساخت یافته طراحی شدند ، عبارتند از: زبان پاسکال ، زبان ادا ((ADA و زبانc . زبان پاسکال،زبان مناسبی برای آموزش برنامه نویسی در دانشگاههاست . زبان ادا برای امور صنعتی، تجاری و نوشتن برنامه های بزرگ بسیار مفید است. زبان c ، به دلیل ویژگیهای خاص خودش، محبوبیت زیادی در دانشگاهها و خارج از دانشگاهها پیدا کرده است. ویژوال بیسیک زبان جدیدی است که با سرعت در حال رشد است.
3-1-3) برنامه نویسی شیءگرا
برنامه نویسی شیءگرا شیوه نوینی است که در آن می توان قطعاتی را ایجاد کرد و در برنامه های مختلف مورد استفاده قرار داد . قابلیت خوانایی برنامه هایی که در این روش نوشته می شوند بالا بوده ، تست ، عیب یابی و اصلاح آنها آسان است . شیء گرایی ، بر اشیاء تاکید دارد.
تعدادی از زبان هابرای برنامه نویسی شیء گرا طراحی شده اند. زبان اسمالتالک یک زبان برنامه نویسی کاملاشیءگرا است. زبانC++ که تکامل یافته زبان C است، دارای ویژگیهایی است که برنامه نویسی شیءگرادرآن امکان امکان پذیر است. در این زبان، برنامه نویسی ساخت یافته نیز امکان پذیر است. ویژوال بیسیک زبانی کاملا شیءگرا است.
برنامه نویسی شیءگرا داده ها(صفات) ، توابع(رفتارها) را دربسته های به نام اشیاء، بسته بندی می کند . داده ها و توابع هر شیء شدیدا به هم گره خورده اند . اشیاء دارای ویژگی پنهان سازی اطلاعات اند. یعنی گرچه اشیاء ممکن است طریقه ارتباط با اشیای دیگر را از طریق رابط بدانند ، ولی اجازه ندارند که از چگونگی پیاده سازی اشیای دیگر آگاه باشند. به عبارت دیگر، جزییات پیاده سازی ، در داخل اشیاء مخفی شده است . برای آشنایی با این مفهوم ، راننده ای را در نظر بگیرید که بدون آشنایی با جزییات عملکرد موتور اتومبیل ، سیستم تخلیه و جابجایی ، می تواند به خوبی رانندگی کند.
3-2) فرمهای برنامه
فرم اساس کار تمام برنامه های ویژوال بیسیک است . طراحی برنامه در فرم انجام می شود و عناصر برنامه در این فرم قرار می یرند. هر وقت ویژوال بیسیک راه اندازی می شود. فرمی در اختیار برنامه نویس قرار می گیرد تا برنامه خود را در آن فرم طراحی کند. فرم همانند پنجره ای در ویندوز است و نمونه ای از آن در شکل (3-1)آمده است.
شکل(3-1) نمونه ای از فرم
3-3) انواع داده ای
یکی از جنبه های مهم هر زبان برنامه سازی که باید مورد بررسی قرار گیرد،انواع داده ای آن است.روزمره با داده هایی مثل میزان خرید روزانه و اسامی افراد سروکار داریم. خرید روزانه را به صورت اعدادی مثل 1500، 5/143و اسامی افراد را با کلماتی مثل محمد ، حسن و سجاد،بیان میکنیم. انواع داده ها در ویژوال بیسیک علارتند از داده های عددی،رشته ای ، تاریخ و بولین.
3-3-1) داده های عددی
در ویژوال بیسیک از 7 نوع داده عددی استفاده می شود که در جدول( 3-1) آمده است. در استفاده از نوع عددی دقت داشته باشید که از نوع مناسبی برای اعداد استفاده کنید.به عنوان مثال،اگر با عدد کوچکی سروکارداریدکه حداکثر تا 255 است از نوع Byte استفاده کنید و چنانچه نوع صحیح پاسخ گویی نیازشماست از نوع اعشاری استفاده نکنید.
نوع میزان حافظه(بایت) بازه قابل قبول
Byte 1 0 تا 255
Integer 2 32768- تا 32767
Long 4 2147483648- تا 2147483647
Single 4 منفی از 38+E402823/3- تا 45-E401298/1-
مثبت از 45-E401298/1 تا 38+E402823/3
Double 8 منفی از -1/79769313486232+E308 تا
324-E94065645841247/4-
مثبت از 324- E94065645841247/4 تا
1/79769313486232+E308
Currency 8 از 5808/ 922337203685477 تا 5807/ 922337203685477
Decimal اگر از اعشار استفاده شود در بازه
9228162514264337593543950335/7+-
و اگر از اعشار استفاده نشود در بازه
79228162514264337593543950335 +/-
جدول(3-1) مربوط به انواع داده های عددی
3-3-2) انواع غیر عددی
در ویژوال بیسیک علاوه بر نوع عددی،از انواع دیگری نیز استفاده می گرددکه در جدول (3-2) آمده اند.
نوع میزان حافظه(بایت) بازه قابل قبول
String(طول ثابت) طول رشته از یک تا 65400 کاراکتر
String (طول متغییر) 10 بایت + طول رشته از 0 تا 2 میلیارد کاراکتر
Date 8 تاریخ قابل قبول
Boolean 2 True یا False
Variant (عددی) 16 به اندازه نوع عددی Double
Variant (رشته ای) 22 + طول مانند رشته طول متغیر
جدول(3-2) مربوط به انواع غیر عددی
نوع رشته ای : رشته دنبا له ای از کاراکترها است، مثل "Mohammad" نوع رشته ای معمولا برای ذخیره سازی اسامی افراد و سایر متنها به کار می رود و به صورت طول متغیر و طول ثابت استفاده می شود.
نوع بولین : این نوع که نوع منطقی نیز نامیده می شود،داده هایی را نشان می دهد که می تواند دو مقدار درستی یا نادرستی را بپذیرند که به ترتیب با Trueو Falseنمایش داده می شوند.
نوع تاریخ : تاریخ و زمانرا می توان در ویژوال بیسیک به عنوان یک نوع مورد استفاده قرار داد،برای این منظور باید در دو طرف آنها علامت # قرارگیرد.
نوع Variant : از این نوع معمولا در مواردی استفاده می شود که از یک محل حافظه برای ذخیره چندین نوع استفاده می گردد.یعنی یک محل Variantبرای ذخیره موقت هرنوع داده هابه کارمی رودکه این داده هابعدادرمحل دیگری با نوع مشخص ذخیره می شوند.این نوع ،تمام انواع داده ها به جزء رشته ای با طول ثابت را نگه داری می کند.
3-4) راه اندازی ویژوال بیسیک
برنامه ویژوال بیسیک بر روی سی دی ذخیره شده است که برای استفاده از آن باید آن را در دیسک سخت نصب کنید.در محیط ویندوز،برنامه Setup را از روی سی دی اجرا کنید تا ویژوال بیسیک در منوی Programs ویندوز ظاهر شود .برای اجرای آن بر روی گزینه مربوط کلیک کنید تا صفحه اول ویژوال بیسیک مانند شکل(3-2) ظاهر شود.در این شکل می توانید کارهای مورد نظرتان را شروع کنید سیستم به طور خودکار بر روی Standard.exe قرار دارد که برای ایجاد پروژه های ویژوال بیسیک به کار می رود.برای ادامه کار،کلید Enter را فشار دهید یا دکمه Open را در این شکل کلیک کنید.اکنون شکل (3-3)را خواهید دید که درآن ،پنجره ای به نام Form1 ظاهر شده است این Form را در شکل (3-3) نیز مشاهده کردید.Form محیطی است که در آن می توانید برنامه خود را طراحی کنید یعنی عناصر تشکیل دهنده برنامه در این فرم قرار می گیرد.
در شکل(3-3)پنجره های Project ،Properties وForm Layout قرار دارند.هر یک از این پنجره ها را به طور مختصر توضیح می دهیم.
شکل (3-2) صفحه اول ویژوال بیسیک
فرمت این مقاله به صورت Word و با قابلیت ویرایش میباشد
تعداد صفحات این مقاله 44 صفحه
پس از پرداخت ، میتوانید مقاله را به صورت انلاین دانلود کنید





 این مطلب از مطالب آزاد موجود در اینترنت جمع آوری شده است و در مورد انبار دادهها و در 9 صفحه می باشد و در زیر قسمتی از متن آورده شده است :
این مطلب از مطالب آزاد موجود در اینترنت جمع آوری شده است و در مورد انبار دادهها و در 9 صفحه می باشد و در زیر قسمتی از متن آورده شده است :